

- cross-posted to:
- fuck_ai@lemmy.world
- brainworms@lemm.ee
- Tech@europe.pub
- cross-posted to:
- fuck_ai@lemmy.world
- brainworms@lemm.ee
- Tech@europe.pub
Text to avoid paywall
The Wikimedia Foundation, the nonprofit organization which hosts and develops Wikipedia, has paused an experiment that showed users AI-generated summaries at the top of articles after an overwhelmingly negative reaction from the Wikipedia editors community.
“Just because Google has rolled out its AI summaries doesn’t mean we need to one-up them, I sincerely beg you not to test this, on mobile or anywhere else,” one editor said in response to Wikimedia Foundation’s announcement that it will launch a two-week trial of the summaries on the mobile version of Wikipedia. “This would do immediate and irreversible harm to our readers and to our reputation as a decently trustworthy and serious source. Wikipedia has in some ways become a byword for sober boringness, which is excellent. Let’s not insult our readers’ intelligence and join the stampede to roll out flashy AI summaries. Which is what these are, although here the word ‘machine-generated’ is used instead.”
Two other editors simply commented, “Yuck.”
For years, Wikipedia has been one of the most valuable repositories of information in the world, and a laudable model for community-based, democratic internet platform governance. Its importance has only grown in the last couple of years during the generative AI boom as it’s one of the only internet platforms that has not been significantly degraded by the flood of AI-generated slop and misinformation. As opposed to Google, which since embracing generative AI has instructed its users to eat glue, Wikipedia’s community has kept its articles relatively high quality. As I recently reported last year, editors are actively working to filter out bad, AI-generated content from Wikipedia.
A page detailing the the AI-generated summaries project, called “Simple Article Summaries,” explains that it was proposed after a discussion at Wikimedia’s 2024 conference, Wikimania, where “Wikimedians discussed ways that AI/machine-generated remixing of the already created content can be used to make Wikipedia more accessible and easier to learn from.” Editors who participated in the discussion thought that these summaries could improve the learning experience on Wikipedia, where some article summaries can be quite dense and filled with technical jargon, but that AI features needed to be cleared labeled as such and that users needed an easy to way to flag issues with “machine-generated/remixed content once it was published or generated automatically.”
In one experiment where summaries were enabled for users who have the Wikipedia browser extension installed, the generated summary showed up at the top of the article, which users had to click to expand and read. That summary was also flagged with a yellow “unverified” label.
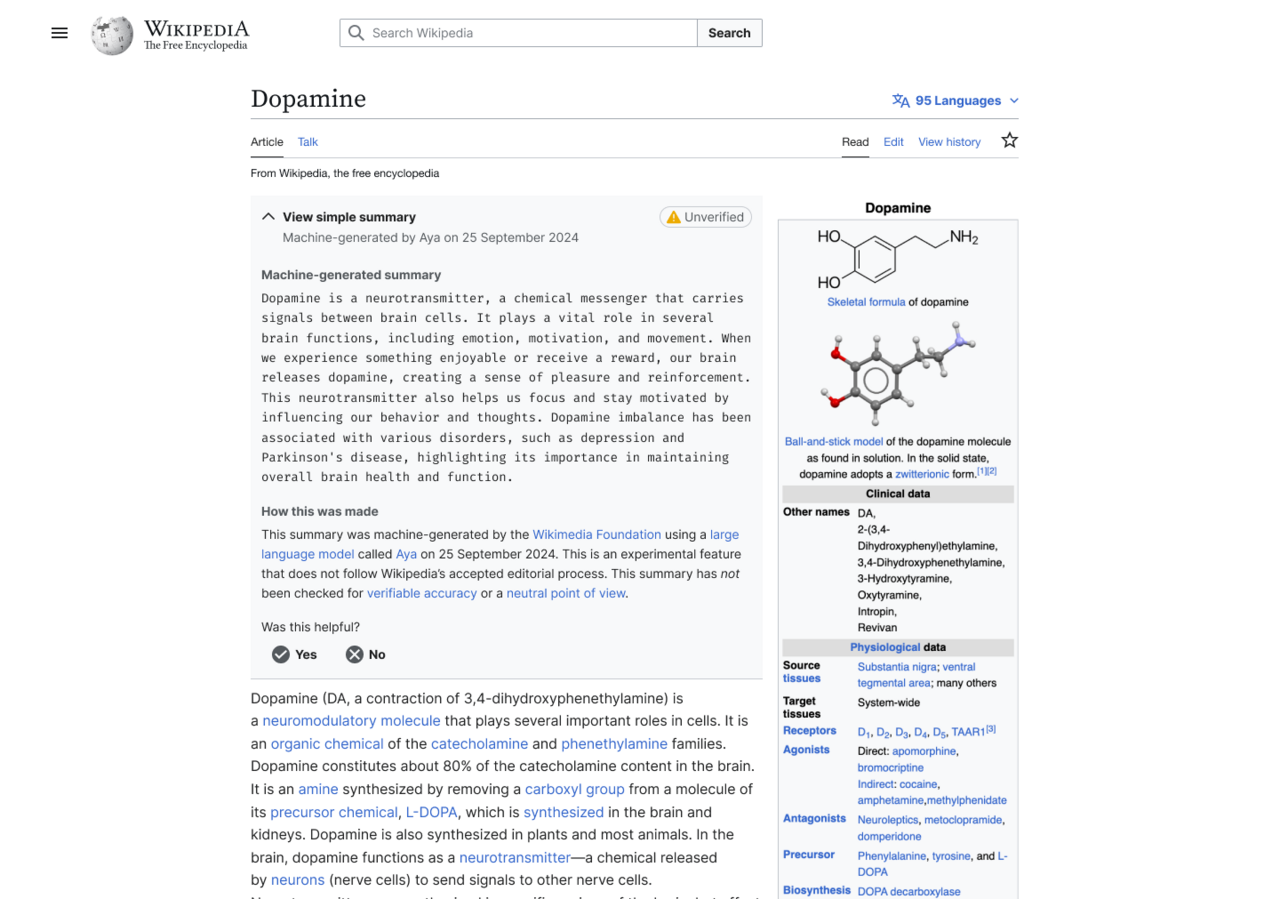
An example of what the AI-generated summary looked like.
Wikimedia announced that it was going to run the generated summaries experiment on June 2, and was immediately met with dozens of replies from editors who said “very bad idea,” “strongest possible oppose,” Absolutely not,” etc.
“Yes, human editors can introduce reliability and NPOV [neutral point-of-view] issues. But as a collective mass, it evens out into a beautiful corpus,” one editor said. “With Simple Article Summaries, you propose giving one singular editor with known reliability and NPOV issues a platform at the very top of any given article, whilst giving zero editorial control to others. It reinforces the idea that Wikipedia cannot be relied on, destroying a decade of policy work. It reinforces the belief that unsourced, charged content can be added, because this platforms it. I don’t think I would feel comfortable contributing to an encyclopedia like this. No other community has mastered collaboration to such a wondrous extent, and this would throw that away.”
A day later, Wikimedia announced that it would pause the launch of the experiment, but indicated that it’s still interested in AI-generated summaries.
“The Wikimedia Foundation has been exploring ways to make Wikipedia and other Wikimedia projects more accessible to readers globally,” a Wikimedia Foundation spokesperson told me in an email. “This two-week, opt-in experiment was focused on making complex Wikipedia articles more accessible to people with different reading levels. For the purposes of this experiment, the summaries were generated by an open-weight Aya model by Cohere. It was meant to gauge interest in a feature like this, and to help us think about the right kind of community moderation systems to ensure humans remain central to deciding what information is shown on Wikipedia.”
“It is common to receive a variety of feedback from volunteers, and we incorporate it in our decisions, and sometimes change course,” the Wikimedia Foundation spokesperson added. “We welcome such thoughtful feedback — this is what continues to make Wikipedia a truly collaborative platform of human knowledge.”
“Reading through the comments, it’s clear we could have done a better job introducing this idea and opening up the conversation here on VPT back in March,” a Wikimedia Foundation project manager said. VPT, or “village pump technical,” is where The Wikimedia Foundation and the community discuss technical aspects of the platform. “As internet usage changes over time, we are trying to discover new ways to help new generations learn from Wikipedia to sustain our movement into the future. In consequence, we need to figure out how we can experiment in safe ways that are appropriate for readers and the Wikimedia community. Looking back, we realize the next step with this message should have been to provide more of that context for you all and to make the space for folks to engage further.”
The project manager also said that “Bringing generative AI into the Wikipedia reading experience is a serious set of decisions, with important implications, and we intend to treat it as such, and that “We do not have any plans for bringing a summary feature to the wikis without editor involvement. An editor moderation workflow is required under any circumstances, both for this idea, as well as any future idea around AI summarized or adapted content.”
You must log in or register to comment.
Aaaaarrgg! This is horrible they stopped AI summaries, which I was hoping would help corrupt a leading institution protecting free thought and transfer of knowledge.
Sincerely, the Devil, Satan
Lucifer is literally the angel of free thought. Satanism promotes critical thinking and the right to question authority. Wikipedia is one of the few remaining repositories of free knowledge and polluting it with LLM summaries is exactly the inscrutable, uncritiqueable bullshit that led to the Abrahamic god casting Lucifer out.
I realize your reply is facetious, but there’s a reason we’re dealing with christofascists and not satanic fascists. Don’t do my boy dirty like that.
Apologies, no offense meant.
Forgiven and forgotten. Want a beer or other culturally appropriate cold, refreshing beverage?
holy shit! Satan has a lemmy account.
I bet they will try again.
Oh absolutely, the
moneyfurnacewikimedia foundation needs to find ways to justify its own existence after all (^:Wouldn’t be surprised, since “no” as a full sentence does not exist in tech or online anymore - it’s always “yes” or “maybe later/not now/remind me next time” or other crap like that…
I know one study found that 51% of summaries that AI produced for them contained significant errors. So AI-summaries are bad news for anyone who hopes to be well informed. source https://www.bbc.com/news/articles/c0m17d8827ko
Two other editors simply commented, “Yuck.”
What insightful and meaningful discourse.
If they’re high quality editors who consistently put out a lot of edits then yeah, it is meaningful and insightful. Wikipedia exists because of them and only them. If most feel like they do and stop doing all this maintenance for free, then Wikipedia becomes a graffiti wall/ad space and not an encyclopedia.
Thinking the immediate disgust of the people doing all the work for you for free is meaningless is the best way to nose dive.
Also, you literally had to scroll past a very long and insightful comment to get to that.
Also, you literally had to scroll past a very long and insightful comment to get to that.
No I didn’t. It’s in the summary, appropriately enough.
I mean, the LLM thing has a proper field for deployment - it can handle the translation of articles that just don’t exist in your language. But it should be a button a person clicks with their consent, not an article they get by default, not a content they get signed by the Wikipedia itself. Nowadays, it’s done by browsers themselves and their extensions.
Wrong community, please repost to the community for Onion articles.
On the one hand, it’s insulting to expect people to write entries for free only to have AI just summarize the text and have users never actually read those written words.
On the other hand, the future is people copying the url into chat gpt and asking for a summary.
The future is bleak either way.
On the third hand some of us just want to be able to read a fucking article with information instead of a tiktok or ai generated garbage. That’s wikipedia, at least it used to be before this garbage. Hopefully it stays true
The ai garbage at the top doesn’t stop you from doing that.
You are correct that it would not instantly become unusable. But when all editors with integrity have ceased to contribute in frustration, wikipedia would eventually become stale, or very unreliable.
Also there is nothing stopping a person from using an llm to summarize an article for them. And the added benefit to that is that the energy and reasources used for that would be only used on the people that wanted to, not on evey single page view. I would assume the enegy consumption on that, would be significant.
I’m willing to bet they would cache the garbage ai summary… not that that makes a difference to your overall point.
when wikipedia starts to publish ai generated content it will no longer be serving its purpose and it won’t need to exist anymore
Too late.
With thresholds calibrated to achieve a 1% false positive rate on pre-GPT-3.5 articles, detectors flag over 5% of newly created English Wikipedia articles as AI-generated, with lower percentages for German, French, and Italian articles. Flagged Wikipedia articles are typically of lower quality and are often self-promotional or partial towards a specific viewpoint on controversial topics.
Human posting of AI-generated content is definitely a problem; but ultimately that’s a moderation problem that can be solved, which is quite different from AI-generated content being put forward by the platform itself. There wasn’t necessarily anything stopping people from doing the same thing pre-GPT, it’s just easier and more prevalent now.
Human posting of AI-generated content is definitely a problem
It isn’t clear whether this content is posted by humans or by AI fueled bot accounts. All they’re sifting for is text with patterns common to AI text generation tools.
There wasn’t necessarily anything stopping people from doing the same thing pre-GPT
The big inhibiting factor was effort. ChatGPT produces long form text far faster than humans and in a form less easy to identify than prior Markov Chains.
The fear is that Wikipedia will be swamped with slop content. Humans won’t be able to keep up with the work of cleaning it out.
deleted by creator
Well, something like it will still need to exist. In which case we can fork because it’s all Creative Commons.
If I wanted an AI summary, I’d put the article into my favourite LLM and ask for one.
I’m sure LLMs can take links sometimes.
And if Wikipedia wanted to include it directly into the site…make it a button, not an insertion.
I like that they are listening to their editors, I hope they don’t stop doing that.
And user backlash. Seriously, wtf?
Yes, throw out the one thing that differentiates you from the unreliable slop.
Is it still possible to see those generated summaries somewhere? Would like to see what their model outputs for some articles, especially compared to the human written lead-in.
As far as I’ve seen they only generated one example summary, which is linked in OP. It’s not good, as Wikipedians have pointed out: https://en.wikipedia.org/wiki/Wikipedia:Village_pump_(technical)#The_Dopamine_summary
I still use Wikipedia monobook, so I had no idea this was a feature.
Summaries for complex Wikipedia articles would be great, especially for people less knowledgeable of the given topic, but I don’t see why those would have to be AI-generated.
the Top section of each wikipedia article is already a summary of the article
Fucking thank you. Yes, experienced editor to add to this: that’s called the lead, and that’s exactly what it exists to do. Readers are not even close to starved for summaries:
- Every single article has one of these. It is at the very beginning – at most around 600 words for very extensive, multifaceted subjects. 250 to 400 words is generally considered an excellent window to target for a well-fleshed-out article.
- Even then, the first sentence itself is almost always a definition of the subject, making it a summary unto itself.
- And even then, the first paragraph is also its own form of summary in a multi-paragraph lead.
- And even then, the infobox to the right of 99% of articles gives easily digestible data about the subject in case you only care about raw, important facts (e.g. when a politician was in office, what a country’s flag is, what systems a game was released for, etc.)
- And even then, if you just want a specific subtopic, there’s a table of contents, and we generally try as much as possible (without harming the “linear” reading experience) to make it so that you can intuitively jump straight from the lead to a main section (level 2 header).
- Even then, if you don’t want to click on an article and just instead hover over its wikilink, we provide a summary of fewer than 40 characters so that readers get a broad idea without having to click (e.g. Shoeless Joe Jackson’s is “American baseball player (1887–1951)”).
What’s outrageous here isn’t wanting summaries; it’s that summaries already exist in so many ways, written by the human writers who write the contents of the articles. Not only that, but as a free, editable encyclopedia, these summaries can be changed at any time if editors feel like they no longer do their job somehow.
This not only bypasses the hard work real, human editors put in for free in favor of some generic slop that’s impossible to QA, but it also bypasses the spirit of Wikipedia that if you see something wrong, you should be able to fix it.
The wikipedia is already the processed food of more complex topics.
I mean that’s kinda why there’s simple english is it not?
For English yes, but there’s no equivalent in other languages.
I thought they had German at least in a simplified version?
Maybe we could generate those with AI… oh wait, I think I see the problem…
Yeah this screams “Let’s use AI for the sake of using AI”. If they wanted simpler summaries on complex topics they could just start an initiative to have them added by editors instead of using a wasteful, inaccurate hype machine
deleted by creator

















